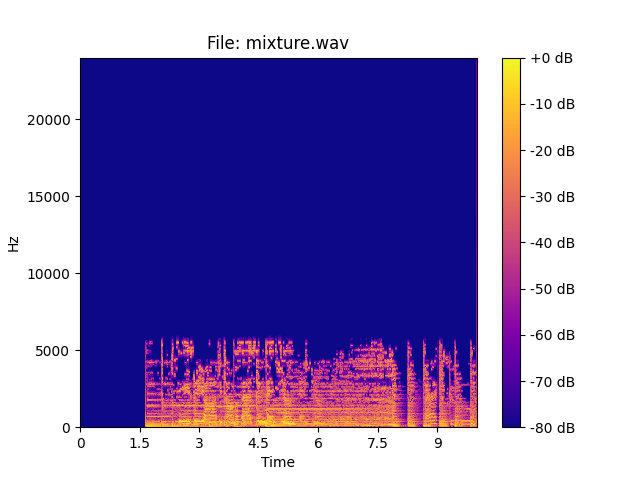
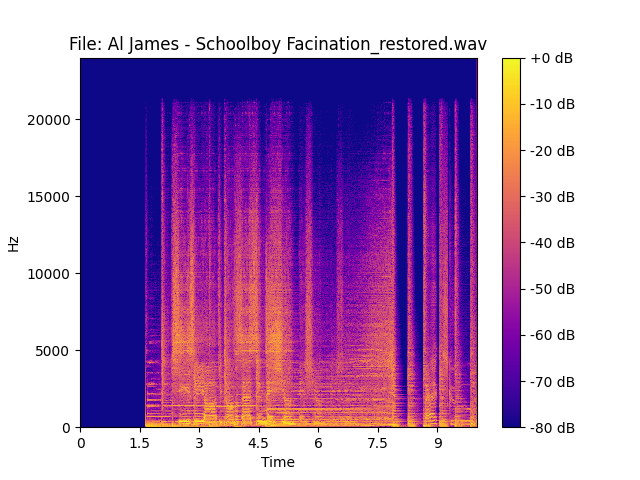
Новости марта 2026
1) Мы добавили iOS-приложение и обновили приложение для Android. Оба они уже доступны. 

В последнем выпуске добавлены следующие функции:
- Проверка автообновлений
- Теперь вы можете отправлять отзывы о результатах разделения прямо как на сайте
- Исправлены ошибки
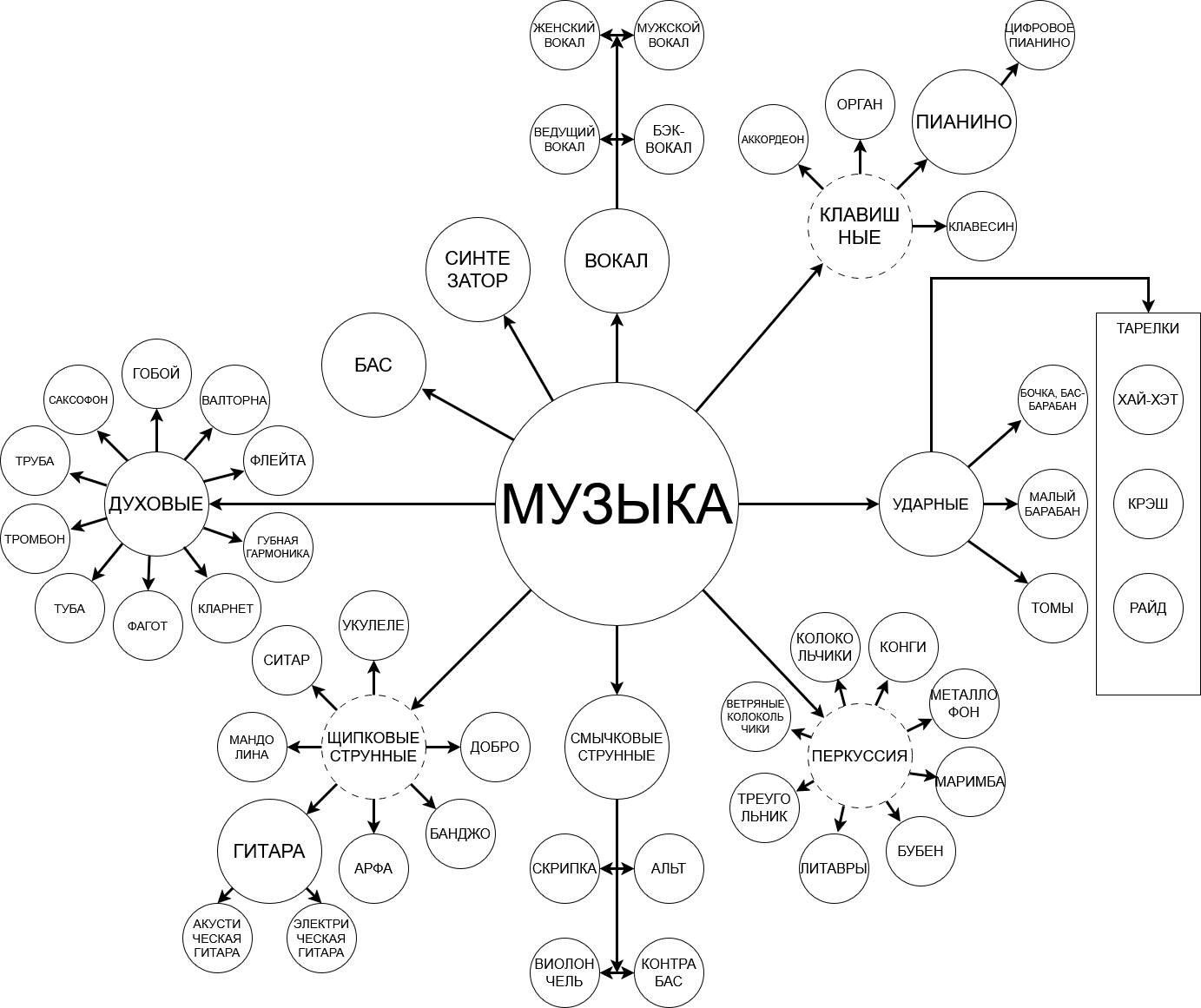
2) Мы представили множество новых моделей для выделения отдельных инструментов:
| 1) MVSep Соло/Ритм-гитара (Демо) | 2) MVSep Щипковые струнные (Демо) | 3) MVSep Перкуссия (Демо) |
| 4) MVSep Клавишные (Демо) | 5) MVSep Медные духовые (Демо) | 6) MVSep Деревянные духовые (Демо) |
| 7) MVSep Ксилофон (Демо) | 8) MVSep Челеста (Демо) | 9) MVSep Хор (Демо) |
| 10) MVSep Волынка (Демо) | 11) MVSep Braam (Демо) | 12) MVSep FX (Эффекты) (Демо) |
Текущую схему разделения можно найти ниже:
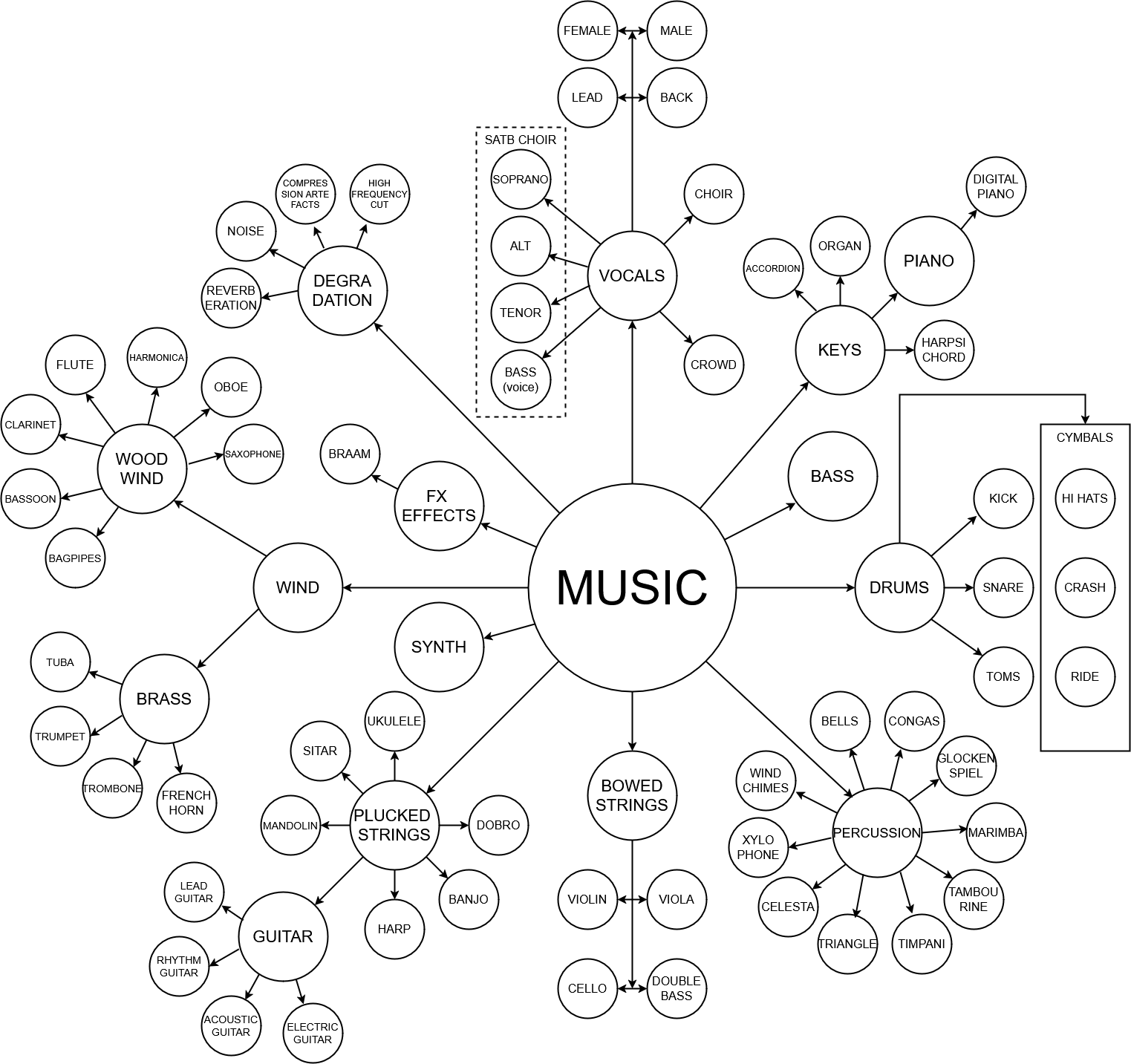

3) Добавлена новая модель MVSep SATB Choir (сопрано, альт, тенор, бас).
Описание: https://mvsep.com/algorithms/104
Демо 1 (вокал)
Демо 2 (вокал)
Демо (струнные)
Огромное спасибо @Dry Paint Dealer Undr за помощь в создании этой модели.
P.S. Модель работает не только с вокалом, но и со струнными и некоторыми другими инструментами.
4) Мы добавили мощную модель VibeVoice в раздел Экспериментальные (Experimental). Она доступна в 2 вариантах: Клонирование голоса (Voice Cloning) и Текст-в-речь (Text-to-Speech).
Ключевые особенности:
- Две модели: small (1.5 млрд параметров) и large (7 млрд параметров)
- До 4 спикеров в одной записи
- До 90 минут генерируемого аудио
- Поддержка языков: официально поддерживаются английский (по умолчанию) и китайский, но проверено, что модель неплохо работает и с другими языками.
- Клонирование голоса: возможность загрузки эталонной аудиозаписи
VibeVoice (Клонирование голоса): Инфо | Демо 1 | Демо 2
VibeVoice (TTS): Инфо | Демо 1
Мы также заметили, что если сэмпл содержит музыку вместе со словами, это может заставить сгенерированный голос петь.
5) Мы добавили новую модель для удаления звуков толпы на базе архитектуры BSRoformer. Она доступна в разделе "MVSep Crowd removal (crowd, other)" под названием "BS Roformer (SDR crowd: 7.21)". SDR увеличен с 6.27 до 7.21.
6) Добавлены три новые модели для вокала.
В BS Roformer (vocals, instrumental):
- unwa BS Roformer HyperACE v2 instrum (SDR instrum: 17.40)
- unwa BS Roformer HyperACE v2 vocals (SDR vocals: 11.39)
В MelBand Roformer (vocals, instrumental):
- becruily deux (SDR vocals: 11.35, SDR instrum: 17.66)
7) Мы добавили новую модель Transkun. Transkun — это современная open-source модель для автоматической транскрипции фортепианной музыки (Audio-to-MIDI). Официальная страница модели находится здесь. Она считается одной из лучших (SOTA — State of the Art) в своем классе. Модель способна распознавать не только сами ноты, но и их длительность, громкость (velocity), а также использование педали.

8) Мы добавили новую модель Basic Pitch. Basic Pitch — это современная нейросеть от лаборатории Audio Intelligence Lab компании Spotify, которая конвертирует мелодичные аудиозаписи в ноты (формат MIDI). В отличие от устаревших конвертеров, эта модель способна "слышать" не только отдельные ноты, но и аккорды, а также тончайшие нюансы исполнения. Basic Pitch является "независимой от инструмента" (instrument-agnostic) моделью. Это означает, что она одинаково хорошо справляется с различными тембрами:
- Вокал
- Струнные: акустическая и электрогитара, скрипка, виолончель.
- Клавишные: фортепиано, органы и синтезаторы.
- Духовые: флейта, саксофон, труба и другие.
Важно: Модель предназначена для мелодичных инструментов. Она не подходит для ударных или перкуссии, так как фокусируется на высоте звука, а не на ритмическом шуме.
Демо | Описание | Ссылка на модель
9) Мы добавили алгоритм Bark (Speech Gen) в раздел Экспериментальные (Experimental). Bark — это модель на базе трансформера, созданная компанией Suno, которая представляет собой не просто традиционный инструмент синтеза речи, а полноценную генеративную систему "текст-в-аудио". Ее возможности выходят далеко за рамки обычной озвучки: помимо создания высокореалистичной речи на нескольких языках, Bark может генерировать музыку, фоновые шумы и простые звуковые эффекты. Уникальной особенностью модели является способность воспроизводить тонкие невербальные коммуникации, такие как смех, вздохи и плач, что делает итоговый звук максимально живым и естественным.
В наших экспериментах она иногда не следует тексту или инструкциям ) Смотрите демо в качестве примера.
10) Мы добавили Qwen3-TTS, мощную модель генерации речи, предлагающую поддержку клонирования голоса, дизайна голоса, генерации сверхвысококачественной человекоподобной речи и голосового управления на естественном языке. На MVSep мы используем самую большую модель с 1.7 млрд параметров. Модель доступна в 3 вариантах:
- Qwen3-TTS (Custom Voice) - модель с предустановленными спикерами | Демо
- Qwen3-TTS (Voice Design) - модель, способная создавать голос на основе описания | Демо
- Qwen3-TTS (Voice Cloning) - модель, способная клонировать голос на основе эталонного аудиофайла | Демо
11) Мы добавили на сайт новый алгоритм HeartMuLa. Это передовое open-source семейство мультимодальных базовых моделей (лицензия Apache 2.0), предназначенное для высококачественного синтеза музыки и обработки звука. В отличие от проприетарных облачных сервисов (таких как Suno или Udio), HeartMuLa дает разработчикам возможность запускать ее локально на собственном оборудовании. Качество генерируемых песен довольно хорошее.
Официальный репозиторий | Демо 1 | Демо 2 | Документация
Текущие ограничения:
1) Модель плохо следует тегам.
2) Модель вычислительно тяжелая и использует много видеопамяти (VRAM).