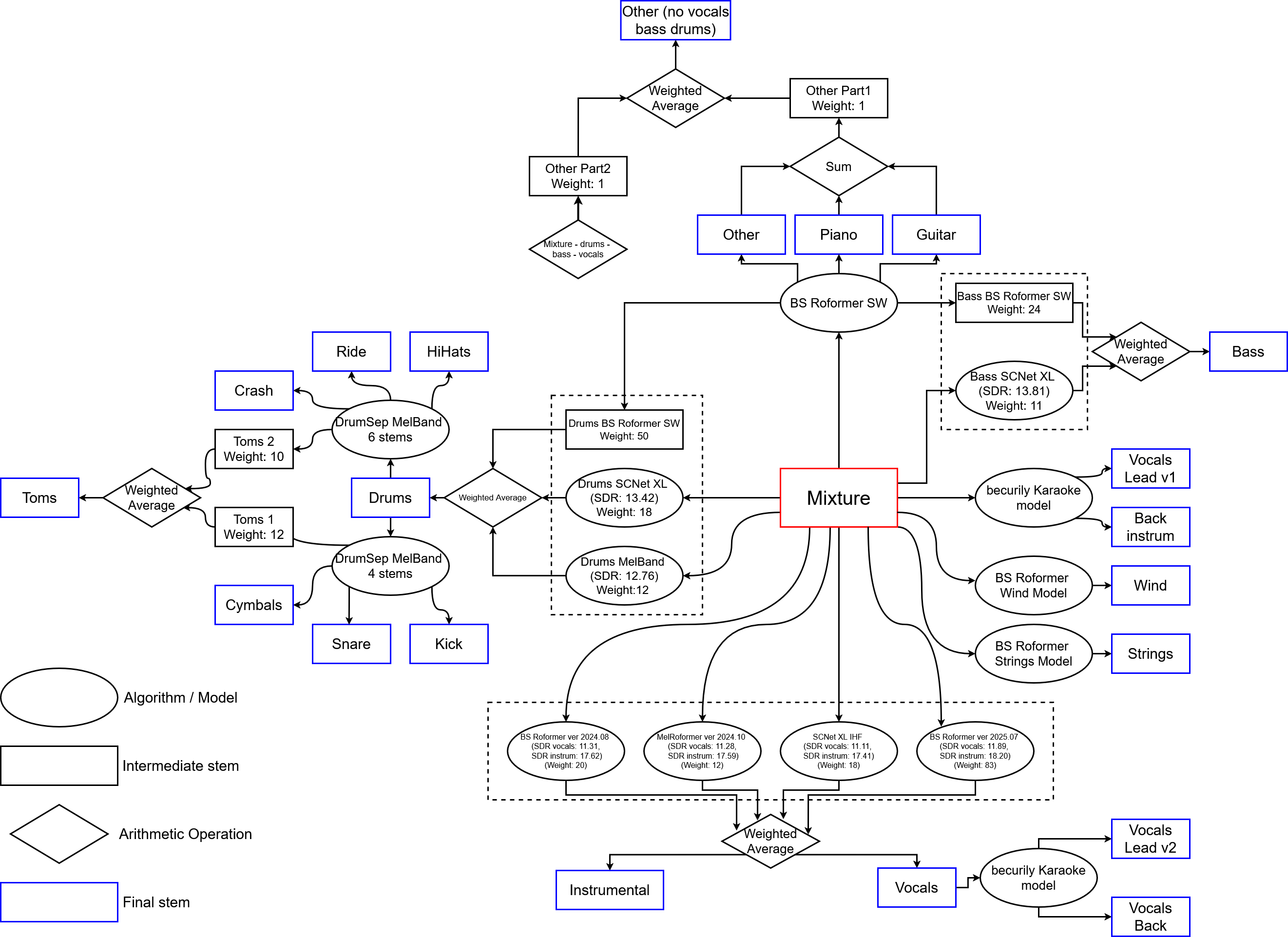
The model separates the drum track into 4, 5, or 6 types: 'kick', 'snare', 'cymbals', 'toms'. In the 5-track models, 'hh' is separated from 'cymbals', and in the case of 6 tracks, 'cymbals' is split into 'hh', 'ride', and 'crash'.
A total of 8 models are available:
1) The DrumSep model from the GitHub repository. It was trained on the HDemucs architecture and splitting drums into 4 tracks.
2) A model based on the mdx23c architecture, prepared by @jarredou and @aufr33. The model splits drums into 6 tracks.
3) A model based on the SCNet XL architecture, which splits drums into 5 tracks.
4) A model based on the SCNet XL architecture, which splits drums into 6 tracks.
5) A model based on the SCNet XL architecture, which splits drums into 4 tracks.
6) Ensemble of 4 models (1 MDX23C + 3 SCNet XL)
7) A model based on the MelBand Roformer architecture, which splits drums into 4 tracks.
8) A model based on the MelBand Roformer architecture, which splits drums into 6 tracks.
All models work only with the drum track. If other instruments or vocals are present in the track, the model will not work correctly. Therefore, the algorithm has two modes of operation. In the first (default) mode, the best model for drums, MVSep Drums, is first applied to the track, extracting only the drum part. Then, the DrumSep model is applied. If your track consists only of drums, it makes sense to use the second mode, where the DrumSep model is applied directly to the uploaded audio.
Quality table (SDR metric, higher is better):
| Algorithm name |
kick |
snare |
toms |
cymbals |
| hh |
ride |
crash |
| DrumSep model by inagoy (HDemucs, 4 stems) |
14.13 |
8.42 |
5.67 |
5.63 |
| DrumSep model by aufr33 and jarredou (MDX23C, 6 stems) |
18.32 |
13.60 |
13.25 |
6.71 |
5.38 |
7.56 |
| DrumSep SCNet XL (5 stems) |
20.21 |
15.05 |
16.28 |
7.05 |
8.56 |
| DrumSep SCNet XL (6 stems) |
20.24 |
14.80 |
15.93 |
6.74 |
5.02 |
7.63 |
| DrumSep SCNet XL (4 stems) |
20.50 |
14.69 |
15.92 |
10.08 |
| Ensemble of 4 models (3 * SCNet + MDX23C) |
20.59 |
15.11 |
16.41 |
7.19 |
5.59 |
7.85 |
| DrumSep Mel Band Roformer (4 stems) |
22.22 |
17.09 |
15.86 |
11.87 |
| DrumSep Mel Band Roformer (6 stems) |
20.21 |
15.33 |
15.48 |
8.79 |
6.96 |
8.79 |
Quality table (L1 Freq metric, higher is better):
| Algorithm name |
kick |
snare |
toms |
cymbals |
| hh |
ride |
crash |
| DrumSep model by inagoy (HDemucs, 4 stems) |
74.34 |
62.20 |
73.52 |
68.87 |
| DrumSep model by aufr33 and jarredou (MDX23C, 4 stems) |
78.20 |
71.27 |
84.22 |
80.84 |
86.74 |
79.41 |
| DrumSep SCNet XL (5 stems) |
81.56 |
73.16 |
87.85 |
80.65 |
75.44 |
| DrumSep SCNet XL (6 stems) |
81.63 |
72.75 |
87.46 |
79.97 |
85.73 |
78.67 |
| DrumSep SCNet XL (4 stems) |
81.69 |
72.90 |
88.43 |
73.64 |
| Ensemble of 4 models (3 * SCNet + MDX23C) |
81.91 |
73.41 |
88.24 |
81.12 |
86.91 |
79.41 |
| DrumSep Mel Band Roformer (4 stems) |
84.97 |
77.78 |
90.13 |
78.16 |
| DrumSep Mel Band Roformer (6 stems) |
81.82 |
75.63 |
88.93 |
85.66 |
90.50 |
82.18 |
Quality table (Fullness metric, higher is better):
| Algorithm name |
kick |
snare |
toms |
cymbals |
| hh |
ride |
crash |
| DrumSep model by inagoy (HDemucs, 4 stems) |
13.61 |
18.80 |
20.86 |
15.80 |
| DrumSep model by aufr33 and jarredou (MDX23C, 4 stems) |
18.67 |
17.85 |
18.29 |
12.95 |
15.76 |
14.92 |
| DrumSep SCNet XL (5 stems) |
18.40 |
30.94 |
29.64 |
13.28 |
15.15 |
| DrumSep SCNet XL (6 stems) |
32.03 |
29.43 |
36.04 |
13.64 |
14.05 |
15.05 |
| DrumSep SCNet XL (4 stems) |
29.87 |
30.53 |
48.35 |
17.48 |
| Ensemble of 4 models (3 * SCNet + MDX23C) |
23.89 |
30.06 |
36.19 |
14.23 |
18.34 |
15.43 |
| DrumSep Mel Band Roformer (4 stems) |
19.45 |
23.09 |
40.32 |
16.44 |
| DrumSep Mel Band Roformer (6 stems) |
15.22 |
25.98 |
42.33 |
19.53 |
20.51 |
19.39 |
Quality table (Bleedless metric, higher is better):
| Algorithm name |
kick |
snare |
toms |
cymbals |
| hh |
ride |
crash |
| DrumSep model by inagoy (HDemucs, 4 stems) |
48.04 |
18.25 |
33.85 |
14.65 |
| DrumSep model by aufr33 and jarredou (MDX23C, 4 stems) |
53.25 |
38.81 |
56.08 |
10.52 |
8.17 |
14.55 |
| DrumSep SCNet XL (5 stems) |
53.33 |
26.00 |
51.72 |
7.97 |
12.66 |
| DrumSep SCNet XL (6 stems) |
36.82 |
28.82 |
40.28 |
7.43 |
8.25 |
11.93 |
| DrumSep SCNet XL (4 stems) |
44.34 |
29.05 |
28.87 |
16.35 |
| Ensemble of 4 models (3 * SCNet + MDX23C) |
51.58 |
32.20 |
46.38 |
8.32 |
8.51 |
14.26 |
| DrumSep Mel Band Roformer (4 stems) |
69.11 |
57.86 |
51.44 |
50.52 |
| DrumSep Mel Band Roformer (6 stems) |
74.12 |
52.23 |
46.14 |
35.19 |
31.70 |
36.12 |
@jarredou prepared new DrumSep validation dataset. It consists of 150 small different tracks. 1st part is Drumkits from 001 to 017 (5 tracks for each of these drumkits, with different playing style) are acoustic drums. From 018 to 082 (1 track by drumkit) are electro drums. This dataset is for 5 stems separation of drums: ['kick', 'snare', 'toms', 'hh', 'cymbals']. For 6 stem models 'ride' and 'crash' were sumed up to 'cymbals'. For 4 stem models 'hh' and 'cymbals' were sumed up to 'cymbals'.
Quality table (SDR metric, higher is better):
| Algorithm name |
kick |
snare |
toms |
cymbals |
| hh |
ride |
crash |
| DrumSep model by inagoy (HDemucs, 4 stems) |
10.52 |
6.05 |
4.68 |
5.03 |
| DrumSep model by aufr33 and jarredou (MDX23C, 6 stems) |
14.54 |
9.79 |
10.63 |
3.19 |
6.08 |
| DrumSep SCNet XL (5 stems) |
17.89 |
12.56 |
14.14 |
3.63 |
6.15 |
| DrumSep SCNet XL (6 stems) |
17.74 |
12.43 |
14.24 |
3.39 |
5.91 |
| DrumSep SCNet XL (4 stems) |
17.61 |
12.37 |
13.40 |
7.48 |
| DrumSep Mel Band Roformer (4 stems) |
18.67 |
13.55 |
13.60 |
8.76 |
| DrumSep Mel Band Roformer (6 stems) |
17.46 |
12.64 |
13.69 |
5.05 |
7.06 |
Quality table (L1 Freq metric, higher is better):
| Algorithm name |
kick |
snare |
toms |
cymbals |
| hh |
ride |
crash |
| DrumSep model by inagoy (HDemucs, 4 stems) |
48.68 |
30.27 |
42.44 |
39.26 |
| DrumSep model by aufr33 and jarredou (MDX23C, 6 stems) |
56.95 |
38.31 |
54.65 |
47.47 |
47.39 |
| DrumSep SCNet XL (5 stems) |
61.56 |
43.06 |
60.76 |
48.19 |
47.49 |
| DrumSep SCNet XL (6 stems) |
61.46 |
42.42 |
60.55 |
47.32 |
46.43 |
| DrumSep SCNet XL (4 stems) |
61.59 |
42.91 |
60.46 |
44.65 |
| DrumSep Mel Band Roformer (4 stems) |
65.24 |
47.13 |
63.50 |
49.77 |
| DrumSep Mel Band Roformer (6 stems) |
63.58 |
46.14 |
62.94 |
53.98 |
51.83 |
Quality table (Log WMSE metric, higher is better):
| Algorithm name |
kick |
snare |
toms |
cymbals |
| hh |
ride |
crash |
| DrumSep model by inagoy (HDemucs, 4 stems) |
12.76 |
11.70 |
11.41 |
19.27 |
| DrumSep model by aufr33 and jarredou (MDX23C, 6 stems) |
16.47 |
15.13 |
16.89 |
23.18 |
22.32 |
| DrumSep SCNet XL (5 stems) |
19.54 |
17.69 |
20.12 |
23.59 |
22.39 |
| DrumSep SCNet XL (6 stems) |
19.41 |
17.57 |
20.21 |
23.38 |
22.17 |
| DrumSep SCNet XL (4 stems) |
19.29 |
17.52 |
19.44 |
21.54 |
| DrumSep Mel Band Roformer (4 stems) |
20.27 |
18.62 |
19.63 |
22.74 |
| DrumSep Mel Band Roformer (6 stems) |
19.16 |
17.77 |
19.71 |
24.94 |
23.23 |