1) We have finally released a free Android app. You can find it at the link: Google.Play
2) For paid users, we have added the functionality of simultaneous uploading of multiple files. It can be found in "Batch Upload"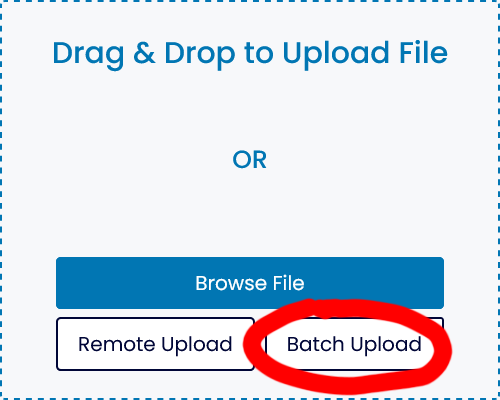
3) Added support for many different audio formats for input files on the site: 'mp3', 'wav', 'opus', 'aac', 'flac', 'm4a', 'ogg', 'wma', 'aiff', 'aif', 'mp4', 'm4v', 'avi', 'mov', 'wmv', 'mkv', 'webm', 'mpg', 'mpeg', '3gp', '3g2', 'ts', 'm2ts', 'mts'.
4) We have created a repository with examples of API usage in Python, including a multifunctional GUI version: https://github.com/ZFTurbo/MVSep-API-Examples
For use under Windows, there is an EXE version that does not require Python or installation. You need to have account at the site to obtain the token.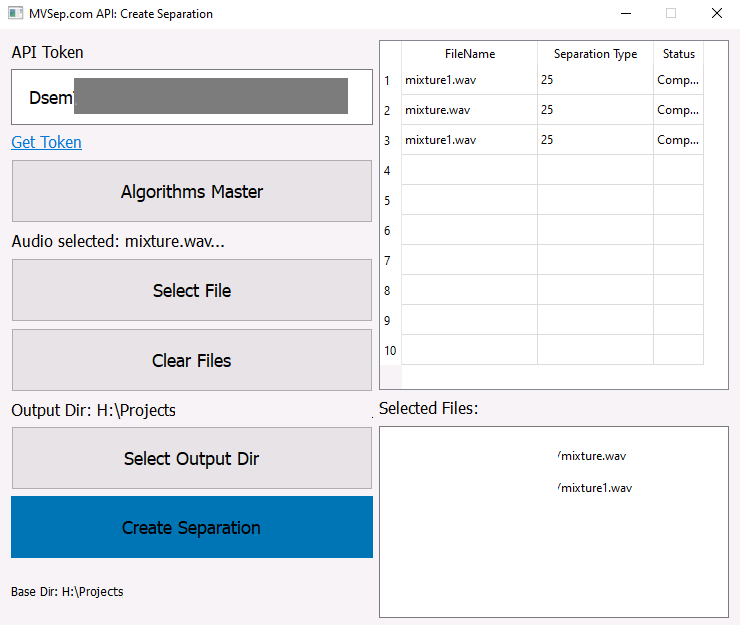
5) We have prepared 3 new LeaderBoards for Quality Checker models:
6) We have added several state-of-the-art (SOTA) models for drum separation. They are based on MelBand Roformer and SCNet XL architectures and offer separations from 4 to 6 stems. The Mel Band Roformer models offer the highest quality separation. The SDR metric table is shown below. More detailed tables can be found on the algorithm description page. Separation is available in the menu as DrumSep (4-6 stems: kick, snare, cymbals, toms, ride, hh, crash).
| Algorithm name | kick | snare | toms | cymbals | ||
| hh | ride | crash | ||||
| DrumSep model by inagoy (HDemucs, 4 stems) | 10.52 | 6.05 | 4.68 | 5.03 | ||
| DrumSep model by aufr33 and jarredou (MDX23C, 6 stems) | 14.54 | 9.79 | 10.63 | 3.19 | 6.08 | |
| DrumSep SCNet XL (5 stems) | 17.89 | 12.56 | 14.14 | 3.63 | 6.15 | |
| DrumSep SCNet XL (6 stems) | 17.74 | 12.43 | 14.24 | 3.39 | 5.91 | |
| DrumSep SCNet XL (4 stems) | 17.61 | 12.37 | 13.40 | 7.48 | ||
| DrumSep Mel Band Roformer (4 stems) | 18.67 | 13.55 | 13.60 | 8.76 | ||
| DrumSep Mel Band Roformer (6 stems) | 17.46 | 12.64 | 13.69 | 5.05 | 7.06 | |
7) Added a new model for MVSep Drums (drums, other) based on SCNet XL with record-breaking metrics for a single model.
| Model | Drums fullness | Drums bleedless | Drums SDR | Drums L1Freq | Other fullness | Other bleedless | Other SDR | Other L1Freq |
| HTDemucs4 | 15.36 | 25.00 | 12.04 | 37.47 | 33.03 | 37.22 | 16.56 | 38.37 |
| MelBand Roformer | 14.16 | 42.12 | 12.76 | 40.80 | 33.97 | 47.24 | 17.28 | 42.02 |
| SCNet Large | 14.91 | 28.23 | 13.01 | 38.04 | 35.39 | 35.03 | 17.53 | 39.36 |
| SCNet XL | 21.21 | 24.47 | 13.42 | 40.30 | 38.56 | 38.32 | 18.00 | 40.35 |
8) Added 2 models for Super Resolution task, which restore high frequencies.
- AudioSR - algorithm restores high frequencies. It works with all types of audio (e.g., music, speech, dog barking, rain sound, etc.). It was originally trained on monophonic audio, so it may produce unstable results on stereo. Based on the article AudioSR: Versatile audio super-resolution at scale.
Metric on Super Resolution Checker for Music Leaderboard (Restored): 25.3195
Original repository: https://github.com/haoheliu/versatile_audio_super_resolution
Original script for inference, prepared by @jarredou: https://github.com/jarredou/AudioSR-Colab-Fork - FlashSR - audio super-resolution algorithm for restoring high frequencies. Based on the article FlashSR: One-step Versatile Audio Super-resolution via Diffusion Distillation.
Metric on Super Resolution Checker for Music Leaderboard (Restored): 22.1397
Original repository: https://github.com/jakeoneijk/FlashSR_Inference
Inference script by @jarredou: https://github.com/jarredou/FlashSR-Colab-Inference
9) We have added our version of the Apollo model for restoring high frequencies. It is available in the "Apollo Enhancers (by JusperLee and Lew)" section with the "Universal Super Resolution (by MVSep Team)" option. For best model performance, a clear upper frequency limit at the same level is required. Model position on the Leaderboard.
10) For Super Resolution models, which include AudioSR, FlashSR, and Apollo Enhancers, spectrogram output for the first 10 seconds of the track has been added, for both the original and restored versions.
11) We have added a karaoke model from @becruily. It is available as an option in the MelBand Karaoke (lead/back vocals) algorithm. It currently shows one of the best results on the corresponding leaderboard.
12) We have added a new MVSep Saxophone (saxophone, other) model. It has 3 versions: SCNet XL, MelBand Roformer, and Ensemble (SCNet + Mel).
- SCNet XL (SDR saxophone: 6.15)
- MelBand Roformer (SDR saxophone: 6.97)
- Ensemble Mel + SCNet (SDR saxophone: 7.13)
13) We have added the "unwa Instrumental v1e plus (SDR vocals: 10.33, SDR instrumental: 16.64)" model from @unwa to the MelBand Roformer (vocals, instrumental) algorithm with high fullness metrics for the instrumental part.