March 2026 News
1) We added an iOS app and updated our Android app. They are both now live. 

The latest release adds the following features:
- Auto-update checker
- You can now send reviews for separations, just like on the website
- Bug fixes
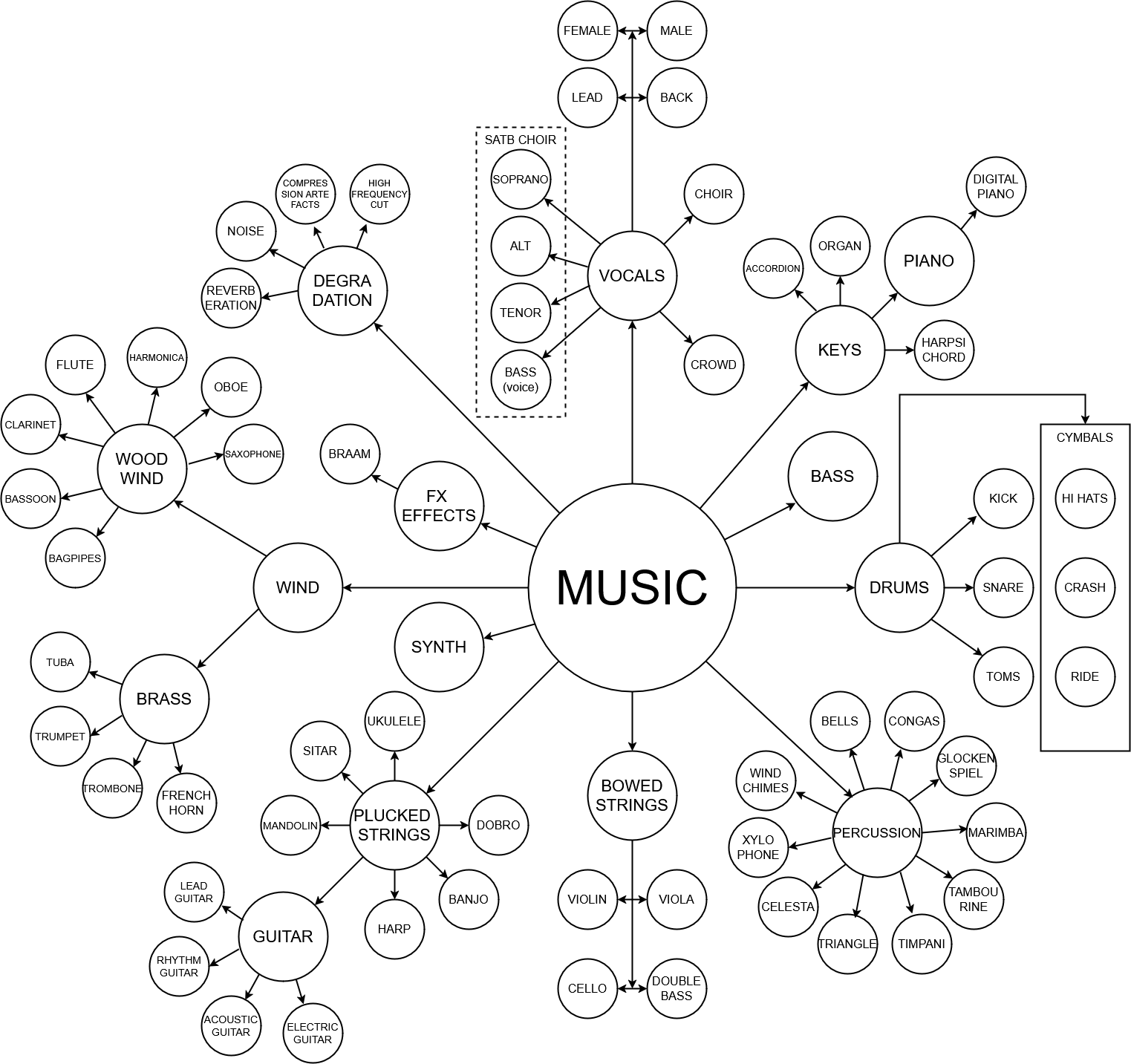
2) We have introduced a variety of new models for separating individual instruments:
| 1) MVSep Lead/Rhythm Guitar (Demo) | 2) MVSep Plucked Strings (Demo) | 3) MVSep Percussion (Demo) |
| 4) MVSep Keys (Demo) | 5) MVSep Brass (Demo) | 6) MVSep Woodwind (Demo) |
| 7) MVSep Xylophone (Demo) | 8) MVSep Celesta (Demo) | 9) MVSep Choir (Demo) |
| 10) MVSep Bagpipes (Demo) | 11) MVSep Braam (Demo) | 12) MVSep FX (Demo) |
The current separation scheme can be found below:

3) A new model, MVSep SATB Choir (soprano, alto, tenor, bass), has been added.
Description: https://mvsep.com/algorithms/104
Demo 1 vocals
Demo 2 vocals
Demo strings
A huge thanks to @Dry Paint Dealer Undr for helping me create this model.
P.S. The model works not only with vocals but also with strings and some other instruments.
4) We added the powerful VibeVoice model to the Experimental section. It is available in 2 variants: Voice Cloning and Text-to-Speech.
Key Features:
- Two models: small (1.5B parameters) and large (7B parameters)
- Up to 4 speakers in a single recording
- Up to 90 minutes of generated audio
- Language support: Officially supports English (default) and Chinese, but it has been verified to work decently for other languages as well.
- Voice cloning: The ability to upload a reference audio recording
VibeVoice (Voice Cloning): Info | Demo 1 | Demo 2
VibeVoice (TTS): Info | Demo 1
We also noted that if a sample contains some music along with words, it can make the generated voice sing.
5) We added a new Crowd removal model based on the BSRoformer architecture. It's available in "MVSep Crowd removal (crowd, other)" under the name "BS Roformer (SDR crowd: 7.21)". The SDR has increased from 6.27 to 7.21.
6) Three new vocal models have been added.
In BS Roformer (vocals, instrumental):
- unwa BS Roformer HyperACE v2 instrum (SDR instrum: 17.40)
- unwa BS Roformer HyperACE v2 vocals (SDR vocals: 11.39)
In MelBand Roformer (vocals, instrumental):
- becruily deux (SDR vocals: 11.35, SDR instrum: 17.66)
7) We added the new Transkun model. Transkun is a modern, open-source model for automatic piano music transcription (Audio-to-MIDI). The official page for the model is here. It is considered one of the best (SOTA — State of the Art) in its class. The model can recognize not only the notes themselves but also their duration, loudness (velocity), and pedal usage.

8) We added the new Basic Pitch model. Basic Pitch is a modern neural network from Spotify’s Audio Intelligence Lab that converts melodic audio recordings into notes (MIDI format). Unlike outdated converters, this model can "hear" not only individual notes but also chords, along with the finest nuances of a performance. Basic Pitch is an "instrument-agnostic" model. This means it handles different timbres equally well:
- Vocals
- Strings: Acoustic and electric guitars, violins, and cellos.
- Keyboards: Pianos, organs, and synthesizers.
- Winds: Flutes, saxophones, trumpets, and others.
Important: The model is designed for melodic instruments. It is not suitable for drums or percussion, as it focuses on pitch rather than rhythmic noise.
Demo | Description | Model link
9) We added the Bark (Speech Gen) algorithm to the Experimental section. Bark is a transformer-based model created by Suno, representing not just a traditional text-to-speech tool, but a fully generative "text-to-audio" system. Its capabilities go far beyond ordinary voicing: besides creating highly realistic speech in multiple languages, Bark can generate music, background noises, and simple sound effects. A unique feature of the model is its ability to reproduce subtle non-verbal communication, such as laughter, sighs, and crying, making the resulting sound maximally alive and natural.
In our experiments, it sometimes doesn't follow the text or instructions. See the demo as an example.
10) We added Qwen3-TTS, a powerful speech generation model offering support for voice cloning, voice design, ultra-high-quality human-like speech generation, and natural language-based voice control. At MVSep, we use the largest 1.7 billion parameter model. The model is available in 3 variants:
- Qwen3-TTS (Custom Voice) - A model with predefined speakers | Demo
- Qwen3-TTS (Voice Design) - A model capable of creating a voice based on a description | Demo
- Qwen3-TTS (Voice Cloning) - A model capable of cloning a voice based on a reference audio file | Demo
11) We added the new HeartMuLa algorithm to the site. It is an advanced open-source family of multimodal foundation models (Apache 2.0 license) designed for high-quality music synthesis and audio processing. Unlike proprietary cloud services (such as Suno or Udio), HeartMuLa gives developers the ability to run it locally on their own hardware. The quality of the generated songs is quite good.
Official repository | Demos 1 | Demos 2 | Documentation
Current limitations:
1) The model struggles to follow tags.
2) The model is computationally heavy and uses a lot of VRAM.
 Listen to:
Listen to: 
